\otimes $ \otimes $
a blog about (mostly) tensors
Seeing Is Believing #1: Thinking in Penrose Diagrams
February 22, 2026 · — views
Observation 1: The Tensor Renaissance Is Upon Us
Within the last two years, there has been a dramatic surge of research in randomized numerical linear algebra focused on designing efficient algorithms for working with tensors rather than just matrices.
As a researcher in this area, I have felt this shift directly in the volume of relevant weekly arXiv posts related to tensors. I wanted to see whether that intuition could be quantified.
Google recently released Google Trends, which is a nifty tool for tracking how search activity for a topic changes over time. To quantify the rise in tensor-related interest, I collected monthly relative search-volume data (case-insensitive) for the query keywords Tensor network, Tensor decomposition, Tensor Train, Matrix Product State, and Random tensor over the past ten years. I then fit an RBF-kernel Gaussian process and tuned its hyperparameters with an L-BFGS optimizer to regress the data. The results speak for themselves:
$\textbf{Demonstration: Tensor networks are hotter than ever}$. Google search activity for common tensor‑network keywords (2016–2026). The posterior mean of a Gaussian‑process and ±1 standard‑deviation confidence intervals are shown for each dataset. The Y axis “Relative Interest” quantifies the ratio of total search activity in a given month relative to the total search history information in Google’s collective database.
This shift toward tensor-structured linear algebra computation was anticipated in a punchy 1999 research article, “The Ubiquitous Kronecker Product” [1], in which Charles Van Loan (of Matrix Computations [2] fame) argues that algorithms organized around tensor structure would pave the path forward for the next (now current) generation of scientific computing. As active research topics like quantum information and machine learning continue to bleed into the applied mathematics purview, it seems Van Loan’s prediction is finally coming true.
Observation 2: Explicit Tensor Syntax... Kind of Sucks
While it is fantastic that more and more people are becoming interested in tensors, one recurring response I hear from applied mathematicians is that tensor papers are often hard to read and sometimes outright confusing. I share this feeling, and I believe the main contributing factor is the lack of a standardized tensor syntax.
To get a sense of how widespread this issue is, I asked the following question to some of my friends in the randomized linear algebra community.
What do you think about the syntax people use for writing tensors?
These were the responses I received:
"The syntax used in the tensor literature is dense and often hard to intuit, especially when super- and subscripts get out of control, but I also recognize it's typically the result of folks trying to figure out the best notation for their particular paper."
"I've always found notation to be a huge impediment when working with tensors. Learning about tensor diagram notation was a revelation: in an instant, what had been difficult-to-parse collections of symbols suddenly became legible."
"All math is hard and requires effort; writing out tensors looks like it requires a lot of effort."
"When I look at tensors, I feel like I need a second pair of glasses."
"I always find tensor notation overwhelming, but maybe it's more complicated because tensors are more complicated than matrices, and even matrix notation can be a lot."
Each of these individuals is a fantastic researcher in numerical linear algebra. Even so, there is clearly a substantial barrier to entry for working with tensors.
Why Are Tensors Hard to Describe?
In my opinion, tensors become challenging for many people largely because we tend to try reasoning about them the same way we reason about matrices. As soon as we fix a basis in high dimensions and try to write out tensors component-wise, there are simply too many degrees of freedom to track conveniently at once and its very easy to get lost and make errors. The results of trying are often long belabored expressions with an unhealthy number of subscripts and superscripts, sometimes consuming a good fraction of the English alphabet, the Greek alphabet, or, on a bad day, both.
To keep the remainder of this post focused, the tensors we are going to talk about will belong to finite-dimensional real vector spaces with base dimension $d$. In this setting, a tensor is simply an element of a tensor product of such spaces.
For instance, a vector is a first-order tensor $\vv \in \bbR^d$, a matrix is a second-order tensor $\mA \in \bbR^d \otimes \bbR^d$, and more generally an order-$n$ tensor is an element $\tT \in \Rdtensor{n}$. Fix the standard basis $(\ve_i)_{i=1}^d$ of $\bbR^d$. Then any order-$n$ tensor admits the basis expansion
\[\tT = \sum_{i_1=1}^d\cdots \sum_{i_n=1}^d \tT(i_1\cdots i_n)\, \bigKron{n}\ve_{i_r},\]so that $\tT$ is specified by $d^n$ real coefficients $\tT(i_1\cdots i_n)$.
This blog post is the first entry of a series called Seeing Is Believing, so it’s only fair that I show you what this actually looks like:
Example: Tensor basis expansion
Entries:
- $\tT(1,1,1)=-2$
- $\tT(1,1,2)=-1$
- $\tT(1,2,1)=-\tfrac{1}{2}$
- $\tT(1,2,2)=\tfrac{1}{2}$
- $\tT(2,1,1)=1$
- $\tT(2,1,2)=2$
- $\tT(2,2,1)=3$
- $\tT(2,2,2)=4$
Writing out the basis expansion of a single tensor is really not that bad. It even gives us an excuse to use $\texttt{\bigotimes}$, which is always fun. The real issues start to appear when we reason about operations between tensors, such as the (tensor) Kronecker product.
Given an order-$n$ tensor $\tX\in \Rdtensor{n}$ and an order-$m$ tensor $\tY \in \Rdtensor{m}$, even writing down what this operator does requires at least $m+n+5$ unique variables.
\[\tX\otimes\tY = \sum_{i_1=1}^d\cdots \sum_{i_n=1}^d \sum_{j_1=1}^d\cdots \sum_{j_m=1}^d \tX(i_1\cdots i_n)\,\tY(j_1\cdots j_m)\, \Bigl(\bigKron{n}\ve_{i_r}\Bigr)\otimes\Bigl(\bigotimes_{s=1}^m\vf_{j_s}\Bigr).\]Recall that when the tensors are just matrices $\mA \in \bbR^{m \times n}$ and $\mB \in \bbR^{p \times q}$, their Kronecker product is the block matrix
\[\mA \otimes \mB = \begin{pmatrix} a_{11}\mB & \cdots & a_{1n}\mB \\ \vdots & \ddots & \vdots \\ a_{m1}\mB & \cdots & a_{mn}\mB \end{pmatrix} \in \bbR^{mp \times nq}.\]The tensor Kronecker product follows the same principle: entries of one tensor scale full copies of the other. We return to a full definition of this operation later (Jump to the definition) for now though, we can take a peek at what this looks like:
Example: The tensor Kronecker product
Each entry of $\tX$ scales the entire tensor $\tY$; the result is stacked into a larger $4\times 4\times 6$ tensor.
“Index blow-up” is so pervasive that many texts about tensors open with some form of cautionary remark informing the reader that there are rough waters ahead.
“In tensor calculations the maze of indices often makes one lose sight of the very great differences between various types of quantities which can be represented by tensors.”
— Harley Flanders, Differential Forms with Applications to the Physical Sciences [3], 1989, Foreword p. 5
It’s a sad state of affairs when each time a reader sits down with this type of mathematics that a preceding Goosebumps style warning is necessary.
To make matters worse, at the frontier of tensor and tensor-network research, even writing down fully rigorous proofs (for example, approximation guarantees) can become very hard to parse without a second monitor and some emotional support coffee.

$\textbf{Demonstration: Flanders’ maze}$. Some examples of Flanders’ “mazes of indices”. (Taken with permission as representative examples of tensors being cumbersome to analyze from the talented postdoctoral tensor researcher Alberto Bucci [4])
Penrose Diagrams

Really, this blog post is an unabashed love letter to a (partial) solution to the syntactic challenges of working with tensors called Penrose Diagrams.
Like many of us, after a sufficient investment of time, Nobel Laureate Sir Roger Penrose eventually became exhausted with explicit tensor syntax. Unlike many of us, he then proceeded to create an entirely new way of thinking about tensors. His motivation (and frustration) is best captured in his prefacing comments before introducing his diagram notation for the first time in the 1971 paper Applications of Negative Dimensional Tensors [5].
“…Even in the case of ordinary finite dimensional systems we can retain the full flexibility and simplicity of the tensor index notation while eliminating the undesirable basis dependence of the usual notation.
However the above is still subject to the other criticism which is sometimes levelled at such index notations, namely the fact that with many indices, expressions may become cumbersome and all-important index connections are easily misread.
I shall therefore introduce a diagrammatic notation for tensors which in most instances allows connections between indices to be discerned at a glance. (mic drop)”
— Sir Roger Penrose, Applications of Negative Dimensional Tensors, 1971, pg 224
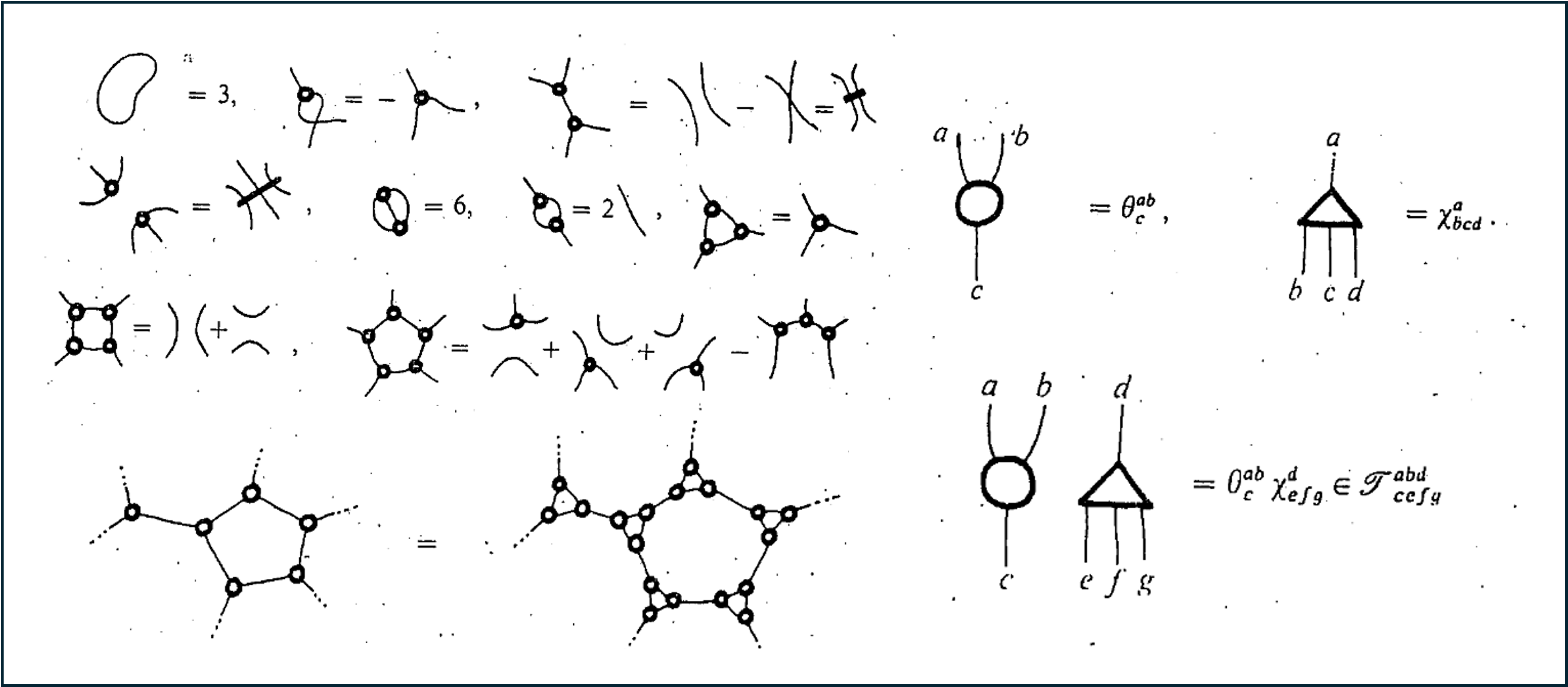
I tried reaching out to Sir Roger Penrose to ask him personally about his thoughts on tensor networks, but received the following response:
$\texttt{This is an automated message}$.
Roger Penrose no longer reads this mailbox.
… Roger is over 90 years old and has much reduced capacity to engage with the wide range of people that still wish to communicate with him.
If you have not heard back within 3 months you are unlikely to do so.
That was about two months ago, so it’s unlikely we’ll find out anytime soon (if ever ☹).
In the remainder of this blog post, I will make the claim that not only are Penrose diagrams the fastest way to reason about tensor contraction, but they are also the best tool for designing tensor network algorithms, since they can reveal the computational complexity of a given method by inspection.
Penrose diagrams are fairly easy to explain but a little more challenging to fully understand. We will start by investing some energy in understanding the two basic tensor operations (the Kronecker product and partial trace) so that tensor contraction can be defined as a one-liner. For additional excellent refreshers on tensor diagrams, see [7, Sec. 3.83], [8, Sec. 2] or [6],[9] which are each beautiful passes on this topic.
Just Draw Circles
Visually, Penrose diagrams are extremely simple. All tensors are drawn as an arbitrary shape, often a circle, with an edge or leg emanating outward for each mode of the tensor. For example, this is how to draw a order 1,2, and three tensor.
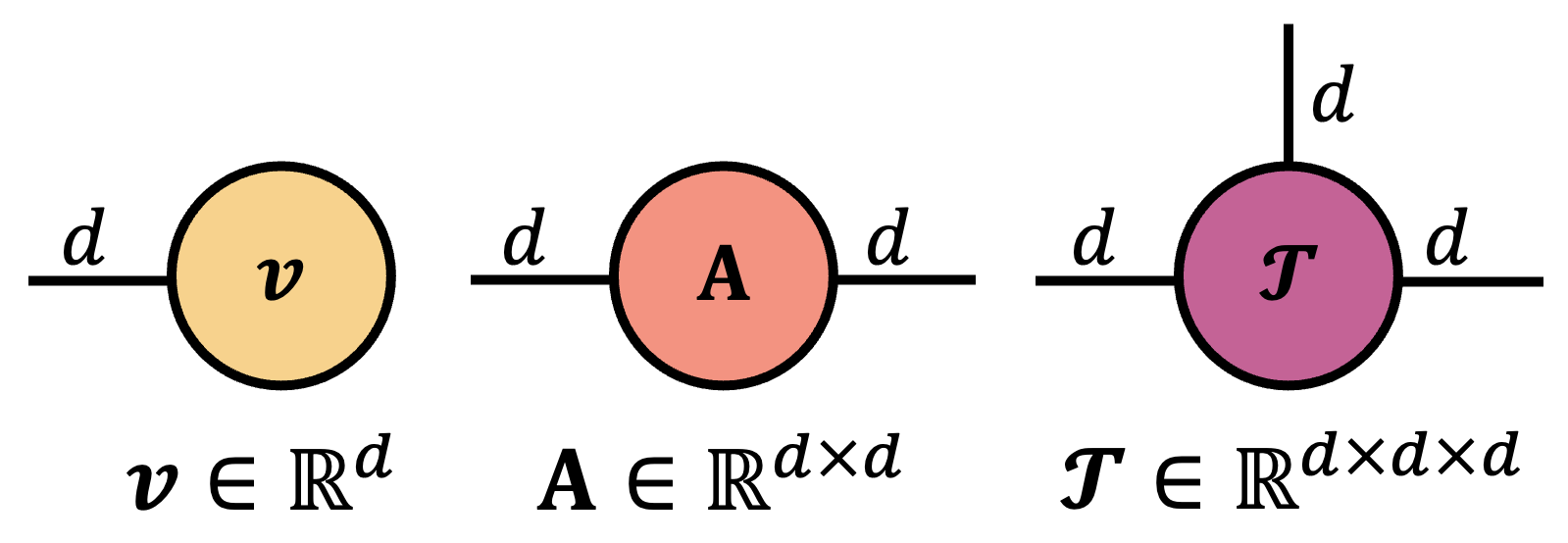
The length and orientation of each leg is also arbitrary, and is generally drawn in whatever way makes it easier to understand what’s going on. Depending on the setting, the shape of a node may be changed from a circle to some other shape to reflect additional structure or set it apart from other tensors.
The Investment: Representing Tensor Contraction
So far, we have mostly just drawn circles and lines. We start to collect dividends once we use this notation to represent contractions.
In a Penrose diagram to contract two tensors along a shared mode, you simply connect the corresponding legs with a line. For example, here are a few softballs from familiar linear algebra settings.

We can extend this idea to include contractions among much larger sets of tensors as well. In the following example, we consider contracting a $3\times 4$ grid of $12$ different tensors together to see how much effort we are saving.
Where we are headed: Penrose notation vs. traditional syntax
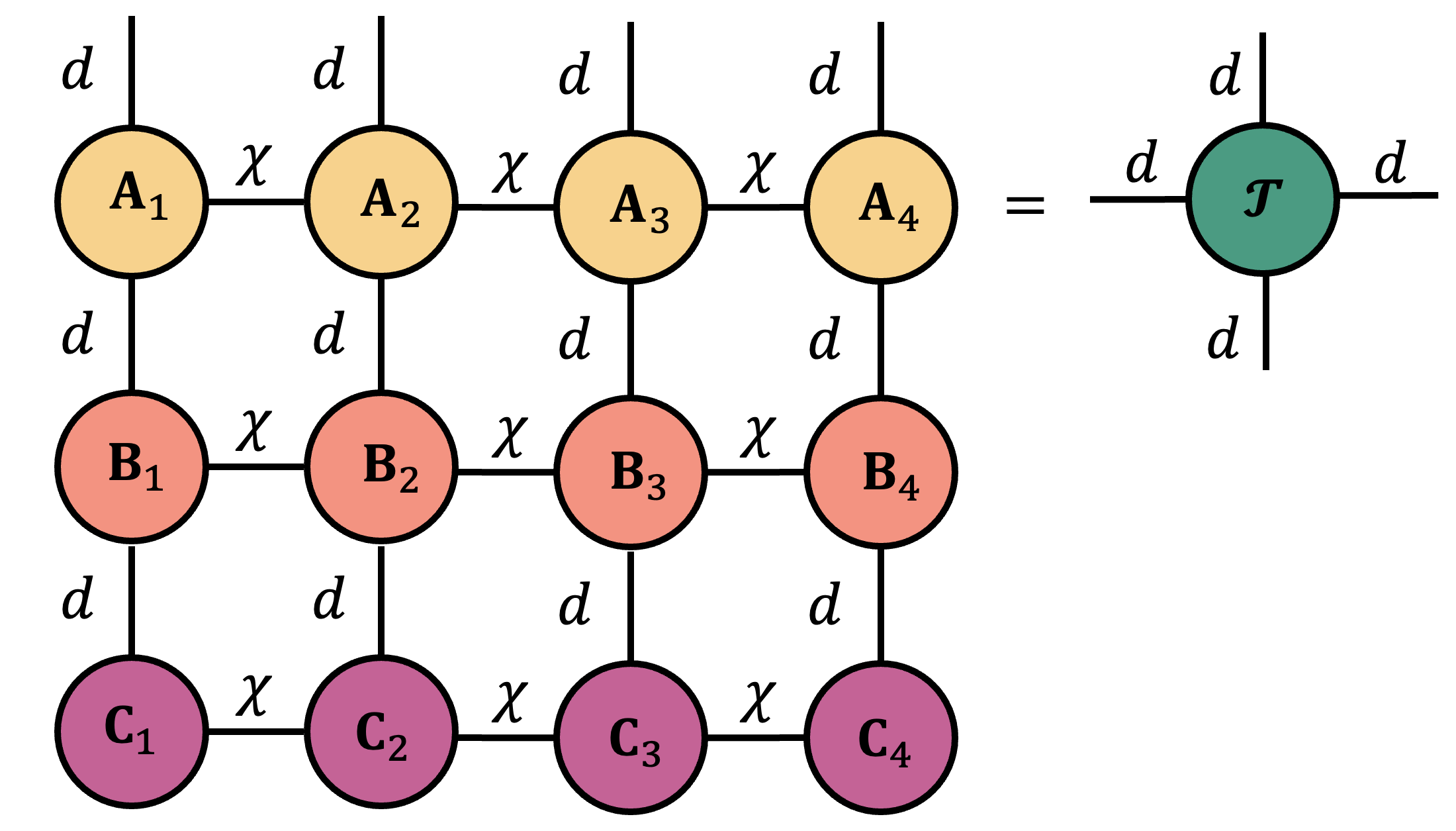
At this point, unless you have worked with Penrose diagrams before, the connection between the left and right columns in the example above is probably not yet obvious. Even so, this small example already shows how Penrose notation compresses information and keeps attention on the outcome of a large contraction rather than getting lost in Flander’s maze of indices.
What’s actually going on here? To understand tensor contraction, we need a way of adding modes and removing modes. Removing a shared mode during contraction should feel fairly intuitive: if two tensors share an index and we contract over it, that index should somehow be “deleted”.
To make this idea rigorous, we first need to understand how to place all modes from two tensors into a single ambient space.
The notation $\tX(\vi)\,\tY(\vj)$ is shorthand here for $\tX(i_1\cdots i_n)\,\tY(j_1\cdots j_m)$. The tensor Kronecker product multiplies two tensors and retains all of their modes. In Penrose notation, the Kronecker product is represented by just placing two tensors next to one another.

When we instead want to remove modes, the operator of choice is the partial trace.
For matrices, the trace operator collapses an entire square matrix to a single scalar. Similarly, if two modes of a given tensor are the same, we can sum over their diagonal, leaving behind a scalar in their wake. Writing down this operation is a bit painful. As consolation, we will see in a moment that in Penrose diagrams this can be represented by drawing a single line.
TLDR: The partial trace replaces two mode indices that each range over $d_\alpha$ values with a single summation, producing a tensor with two fewer modes.
In Penrose notation, the partial trace is represented by drawing a connected line between two modes on the same tensor. Consider tracing over modes 2 and 4 of an order-4 tensor $\tX \in \bbR^{d_1\times d_2\times d_3\times d_4}$ with $d_2=d_4$.
\( \operatorname{tr}_{2,4} \)
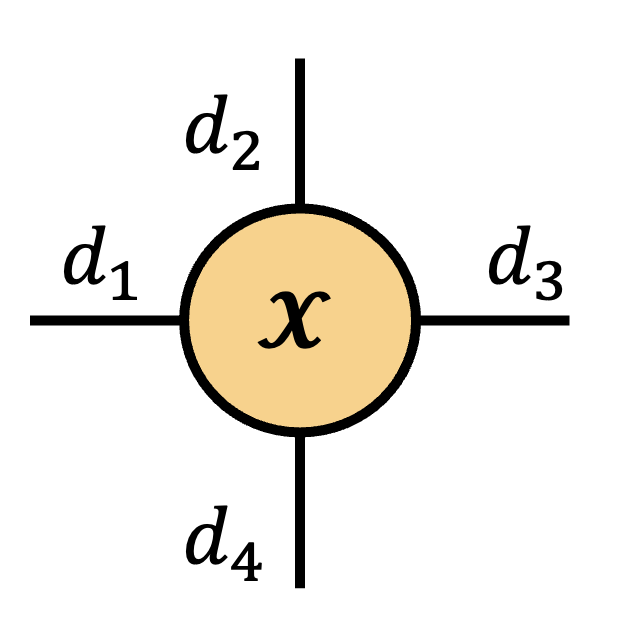 \(=\)
\(=\)
 \(=\)
\(=\)
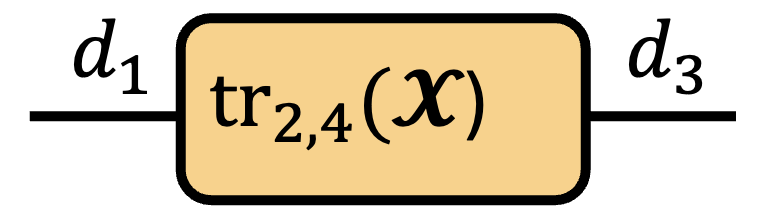
Let’s also see what’s happening structurally when we take a partial trace.
My favorite part about this operator is that the classical notion of summing the diagonal of a matrix is preserved in the geometry of a given tensor.
Example: Partial Trace on a 3×4×3 Tensor
Let $\tX \in \bbR^{3\times 4\times 3}$. The partial trace over modes $1$ and $3$ sums the diagonal fibers $\tX(r, :, r)$ for $r=1,2,3$, producing a single vector in $\bbR^4$.
With these two new operations in hand we are now prepared to define tensor contraction as the Kronecker product followed by a partial trace over the identified pair of modes.
Example: Using the Contracted Product Operator
Below is an example of the contraction of a tensor $\tA_1\in \bbR^{n\times n\times m\times d}$ with another order-4 tensor $\tA_2\in \bbR^{m\times n\times p\times d}$ along their shared mode $m$, highlighted in red for convenience. Also shown is a choice of indexing convention for each tensor. In general, any ordering works as long as it is fixed throughout the analysis, though I typically use clockwise order starting at 9 o'clock (perhaps to the dismay of my friend Guifré Sánchez).
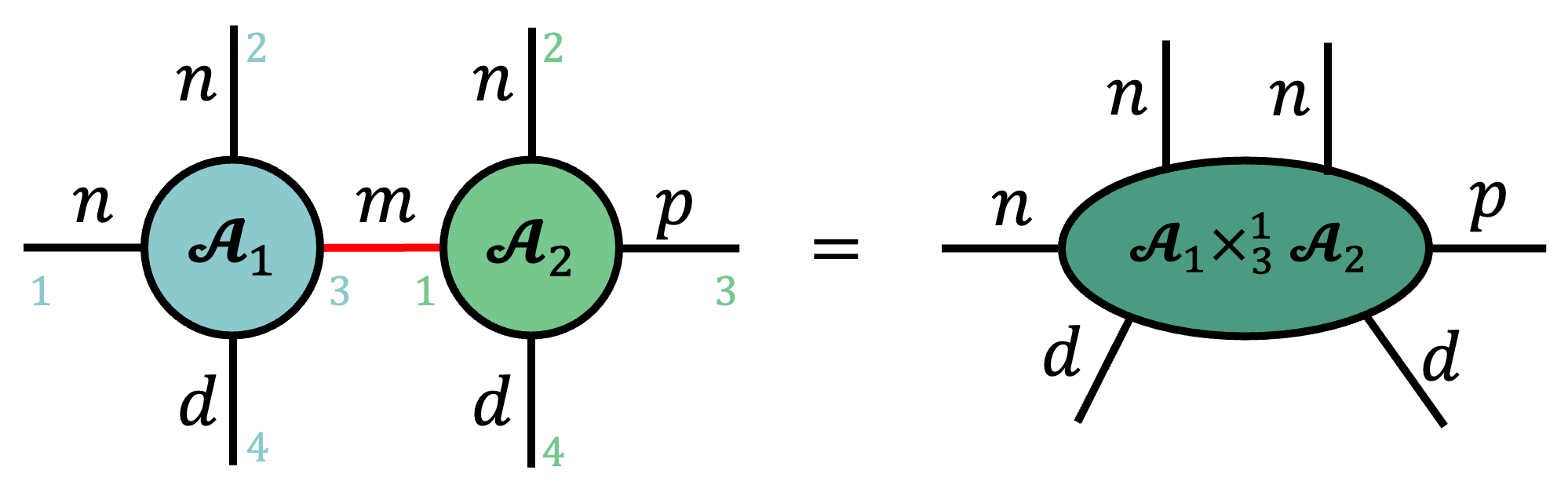
We can also define contractions over multiple modes simultaneously by writing tuples in the superscript and subscript of the contracted product operator.
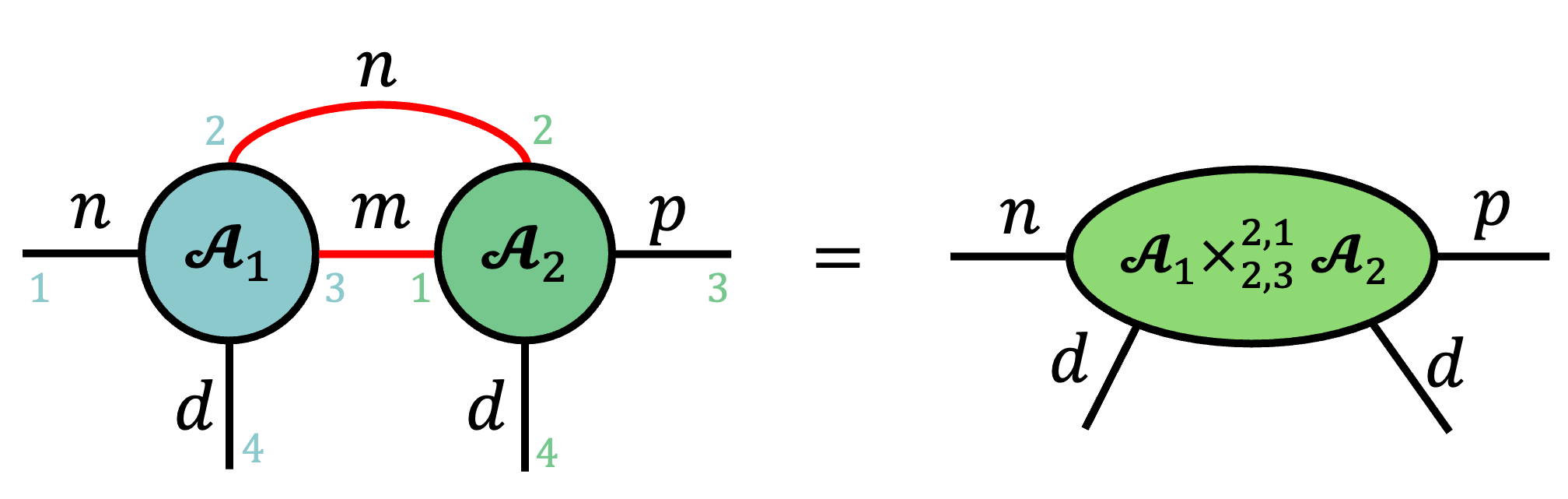
Defining tensor contraction this way is mathematically elegant, but it may not be immediately obvious how to recover simple contractions such as matrix multiplication. Below we show this example and detail how matrix multiplication can be derived as a simple sequence of Penrose diagrams following our definitions above.
Example: Matrix multiplication as tensor contraction
Proposition:
Let $\mA\in \bbR^{n\times m}$ and $\mB\in \bbR^{m\times p}$ be arbitrary real-valued matrices. The matrix product $\mA\mB$ can be written as $\mA\cp{2}{1}\mB$ and is represented by the following Penrose diagram.
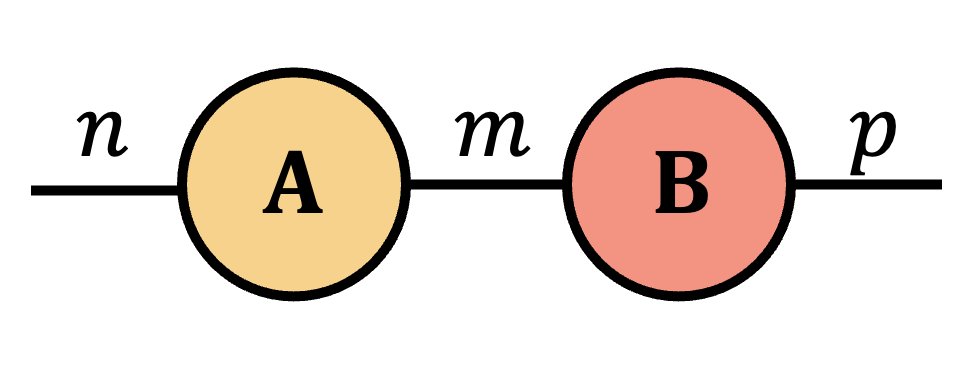 =
=

Proof.
For $\mA\in \bbR^{n\times m}$ and $\mB\in \bbR^{m\times p}$, write $$ \begin{aligned} \mA&=\sum_{i,j}\mA(i,j)\,(\ve_i\otimes \ve_j),\\ \mB&=\sum_{k,\ell}\mB(k,\ell)\,(\ve_k\otimes \ve_\ell). \end{aligned} $$ By the contraction definition, $$ \begin{aligned} \mA\cp{2}{1}\mB &= \operatorname{tr}_{2,1}(\mA\otimes\mB) \\ &= \operatorname{tr}_{2,1}\!\left[\sum_{i,j,k,\ell}\mA(i,j)\,\mB(k,\ell)\, \ve_i\otimes \ve_j\otimes \ve_k\otimes \ve_\ell\right] \\ &= \sum_{i,j,k,\ell}\mA(i,j)\,\mB(k,\ell)\, \operatorname{tr}_{2,1}\!\left(\ve_i\otimes \ve_j\otimes \ve_k\otimes \ve_\ell\right). \end{aligned} $$ Using $$ \begin{aligned} \operatorname{tr}_{2,1}\!\left(\ve_i\otimes \ve_j\otimes \ve_k\otimes \ve_\ell\right) &=\langle \ve_j,\ve_k\rangle\,\ve_i\otimes \ve_\ell \\ &=\delta_{jk}\,\ve_i\otimes \ve_\ell, \end{aligned} $$ we get $$ \begin{aligned} \mA\cp{2}{1}\mB &= \sum_{i,j,\ell}\mA(i,j)\,\mB(j,\ell)\,\ve_i\otimes \ve_\ell \\ &= \sum_{i,\ell}\left(\sum_j\mA(i,j)\,\mB(j,\ell)\right)\ve_i\otimes \ve_\ell \\ &= \sum_{i,\ell}(\mA\mB)(i,\ell)\,\ve_i\otimes \ve_\ell = \mA\mB. \end{aligned} $$
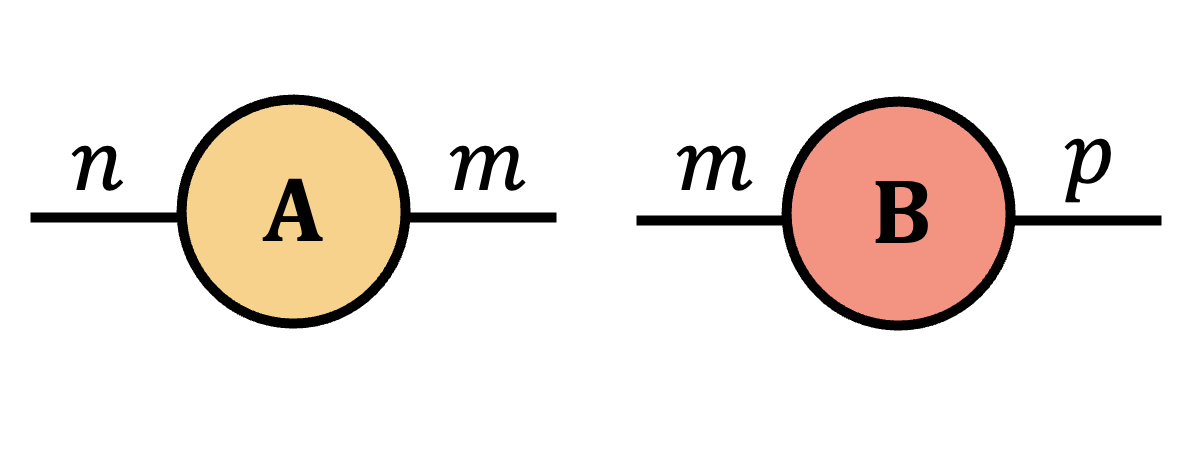

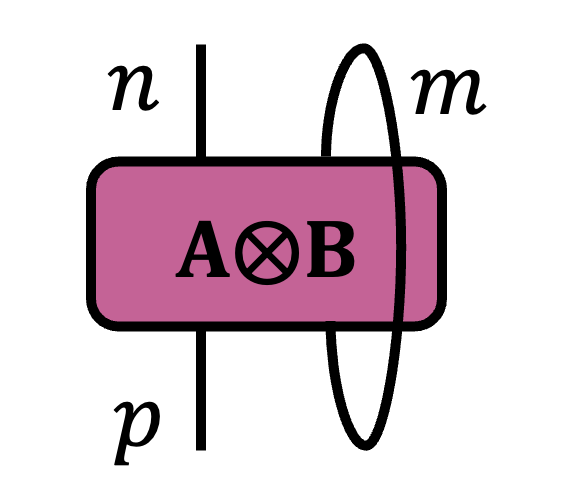

The Payoff: Computational Complexity At A Glance
Now that we have defined Penrose diagrams and formalized what they communicate, I want to highlight one of my favorite consequences of this notation: it provides a direct way to reason about computational complexity when designing linear algebra algorithms.
I first learned this fact from Ethan Epperly some time around July 2023, and it has reshaped how I approach linear algebra and algorithm design. The main idea is the following.
The cost of a single tensor contraction is proportional to the product of the dimensions of all indices that appear in that contraction.
This fact is known in certain corners of the theoretical computer science community concerned with multilinear algebra [pg. 4, 8], and is somewhat immediate once we recognize that contracting two tensors requires accessing all involved entries. Over the last few years, I have started to see it appear more frequently in papers on tensor network methods [10, Figs. 7-9] and I anticipate this idea becoming increasingly standard for analyzing the runtime of tensor network algorithms.
Let’s apply this idea to some contractions we have already seen in this blog post. For each contraction we just write down a big O statement containing the product of all the modes involved.
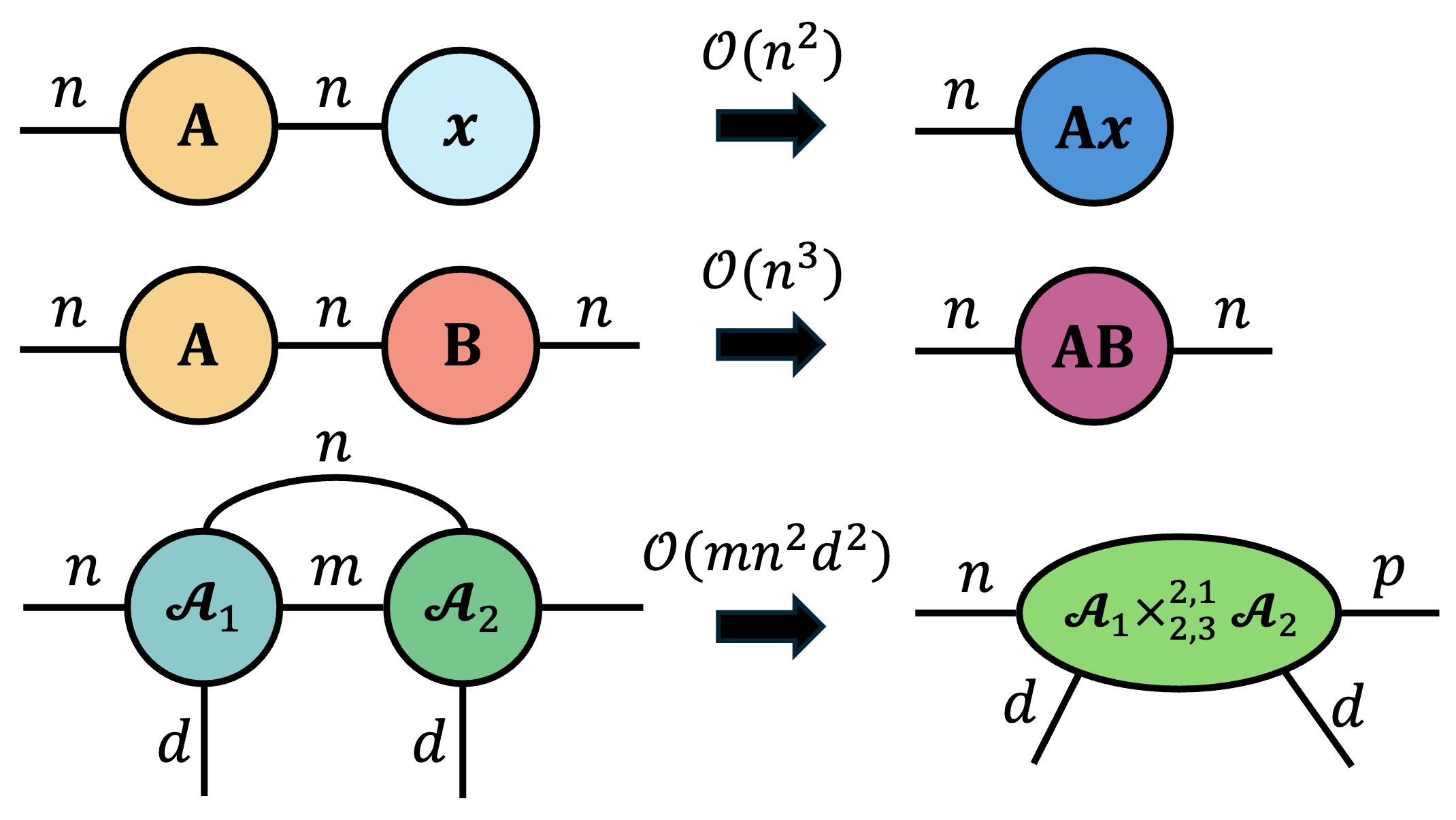
As we can see, we can recover naive bounds for matrix multiplication and matrix-vector multiplication, and we can also quickly recover the cost of a fairly specific tensor contraction.
Things become particularly interesting when we place assumptions on the typical size of the modes of a given tensor. Consider the cost of contracting together the following Penrose diagram.

Depending on the order in which we contract the tensors, we generate different intermediate tensor sizes, which changes the total asymptotic time complexity of the contraction. For instance, here are two contraction sequences that arrive at the same result but have different time complexity.
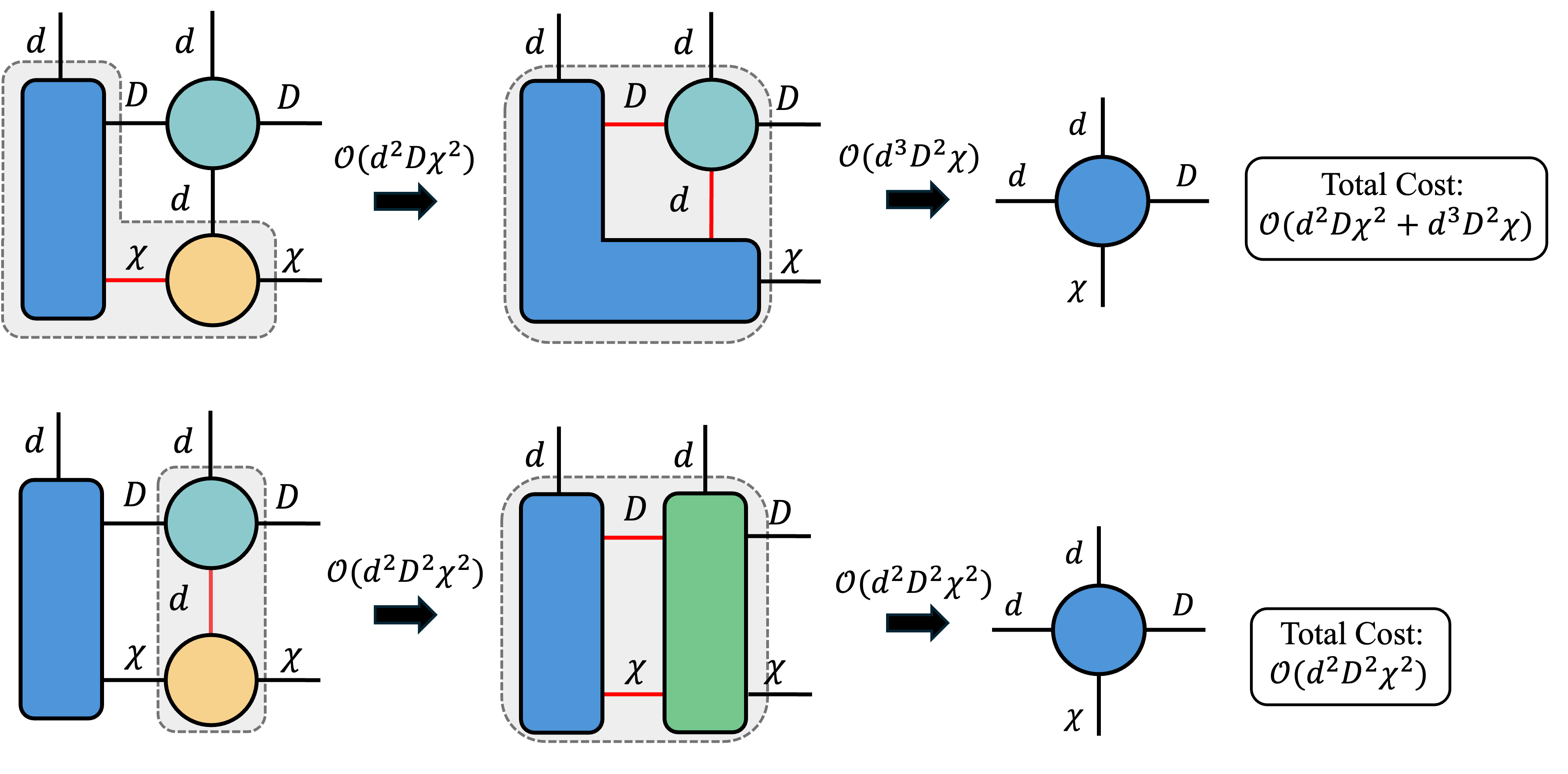
Depending on the relationship between the mode dimensions $d$, $D$, and $\chi$, one of these contraction sequences may be cheaper than another. This specific contraction example above appears very frequently in various tensor network algorithms such as MPO-MPS products, DMRG and others.
In general, identifying optimal tensor contraction sequences is NP-hard [11]. Identifying general-purpose approximate tensor contraction sequences is an active research area (see, for example, [12]). Luckily, in many small-scale examples like the one above, the search space is still tractable (and often fairly straightforward to think about), so near-optimal or optimal contraction paths can often be found a priori to develop fast algorithms.
Closing Remarks
I work in the field of randomized linear algebra, and my research is primarily focused on how randomization can be used for accelerating and developing new tensor network methods.
Both of these fields gain leverage over exact methods by compressing information. Perhaps unsurprisingly, I enjoy Penrose notation for exactly the same reason. The ability to compress tensor operations down to circles and lines is dramatically liberating, and has allowed me to make progress on research problems at a greatly accelerated pace.
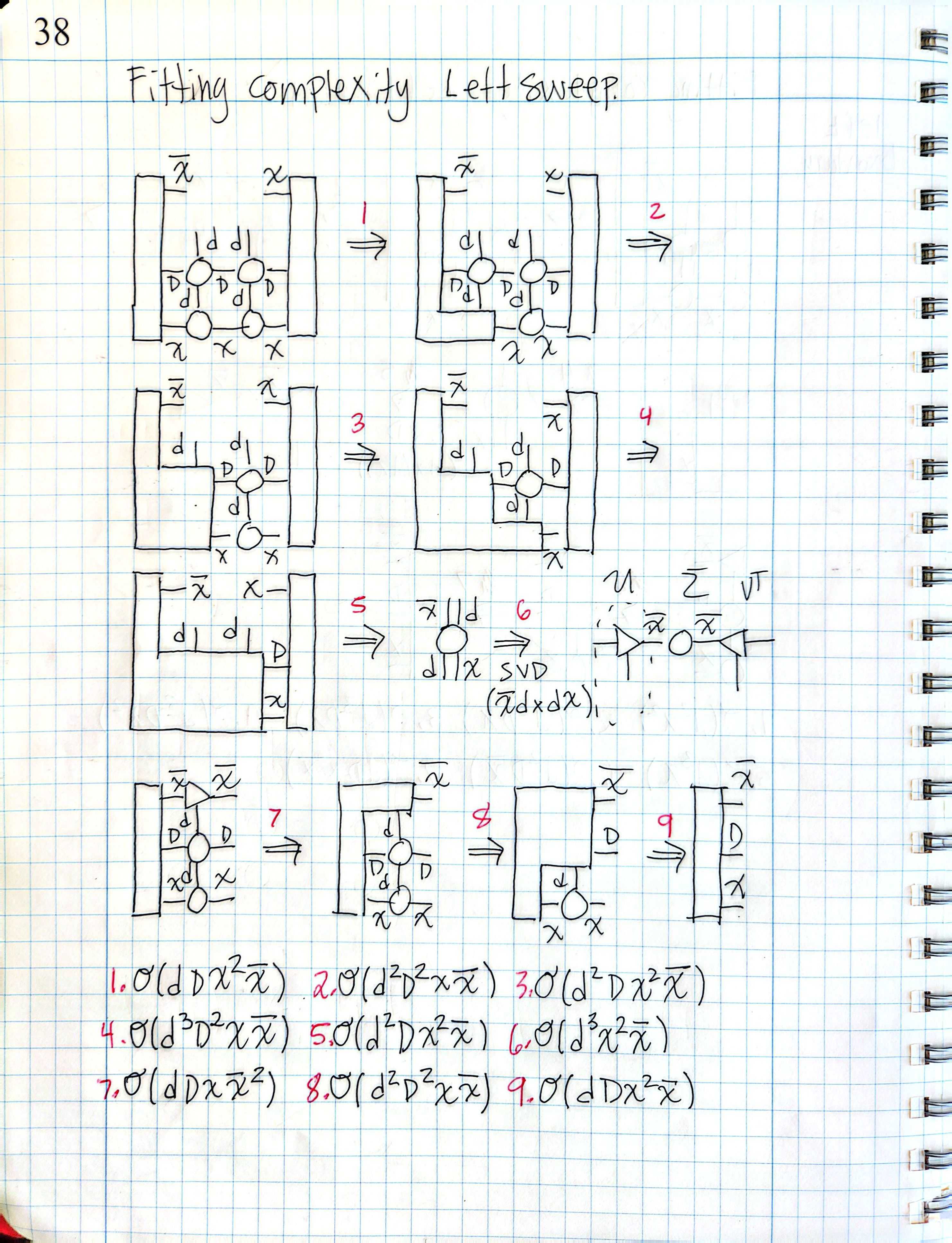
For example, the image on the left is an excerpt from one of my notebooks containing an asymptotic complexity analysis of the tensor contractions within the two-site Fitting (variational) algorithm for the compressed MPO-MPS product [13], which I conducted while working on Successive Randomized Compression (SRC) [14].
This page may have taken about 10 minutes to draw, and it quickly delivered an estimate of how expensive this algorithm was. If I had instead attempted to write a formal analysis in traditional syntax, I am not sure that I would have been brave enough to finish.
In summary, Penrose diagrams are an alternative syntax for thinking about tensor contraction, that makes it very easy to think about tensor algorithms and operations. Hopefully the content of this blog post encourages you to try out Penrose diagrams in your own work, particularly if you are a research scientist studying these methods.
References
- , “The ubiquitous Kronecker product” , Journal of Computational and Applied Mathematics , vol. 123 , no. 1 , pp. 85-100 , 2000 , doi: https://doi.org/10.1016/S0377-0427(00)00393-9 .
- , “Matrix computations” , JHU press , 2013 .
- , “Differential forms with applications to the physical sciences” , Courier Corporation , vol. 11 , 1963 .
- , “Randomized algorithms for streaming low-rank approximation in tree tensor network format” , arXiv preprint arXiv:2412.06111 , 2024 .
- , “Applications of negative dimensional tensors” , Combinatorial mathematics and its applications , vol. 1 , no. 221-244 , pp. 3 , 1971 .
- , “The Tensor Cookbook” , 2024 , https://tensorcookbook.com .
- , “Tensor Decompositions for Data Science” , Cambridge University Press , 2025 .
- , “Hand-waving and interpretive dance: an introductory course on tensor networks” , Journal of Physics A: Mathematical and Theoretical , vol. 50 , no. 22 , pp. 223001 , 2017 , doi: 10.1088/1751-8121/aa6dc3 .
- , “An introduction to graphical tensor notation for mechanistic interpretability” , arXiv preprint arXiv:2402.01790 , 2024 .
- , “Approximate Contraction of Arbitrary Tensor Networks with a Flexible and Efficient Density Matrix Algorithm” , Quantum , vol. 8 , pp. 1580 , 2024 , doi: 10.22331/q-2024-12-27-1580 .
- , “NP-Hardness of Tensor Network Contraction Ordering” , 2023 , https://arxiv.org/abs/2310.06140 .
- , “Hyper-optimized tensor network contraction” , Quantum , vol. 5 , pp. 410 , 2021 , doi: 10.22331/q-2021-03-15-410 .
- , “Renormalization algorithms for Quantum-Many Body Systems in two and higher dimensions” , 2004 , https://arxiv.org/abs/cond-mat/0407066 .
- , “Successive randomized compression: A randomized algorithm for the compressed MPO-MPS product” , 2026 , https://arxiv.org/abs/2504.06475 .
Last updated: February 22, 2026
Comments
Leave a new comment